使用 Astro-Gyoza 搭建博客后一直想加上 AI 摘要功能,看了下 TianliGPT 这样的解决方案,对于我这种没什么流量的小站,使用商业化方案并没有什么太大的意义,于是就有了自己实现一个的想法。
方案设计思路
在实现 AI 摘要功能时,静态博客通常有两种技术路线:构建时生成和访问时生成。考虑到 AI 接口调用的稳定性和成本因素,本方案选择了访问时生成的策略,并通过 Cloudflare 的 Workers、D1 和 KV 构建了一套完整的缓存机制。这种架构不仅能够保证服务的稳定性,还能显著降低运营成本。
功能逻辑与系统架构
页面被访问时将页面的 url 发送到 Worker,Worker 再根据 D1 中是否有缓存摘要、是否过期的判断再进行调用 AI 进行摘要的生成与更新。
Workers 中根据 Accept-Language 或者指定的参数生成对应语言的摘要,摘要更新借助 KV 实现一个锁机制减少 AI 调用(虽然小流量完全用不到)。为了除了网页内容,引入了 https://r.jina.ai 实现 HTML =>> Markdown 的转换(后续也有其他逻辑处理 HTML,但目前还没用到)。
Accept-Language 作为 Prompt 时会出现摘要语言不稳定的情况(可能是不同模型能力问题),所以引入 Cloudflare AI 的小模型以及一张基础数据表构成语言转换功能,实现 zh-CN =>> Chinese (Simplified, China) 的转换。

总体来说响应速度是最优先考虑的因素,总结核心流程就是五个步骤:
- 接收页面访问请求及 URL
- 检查 D1 数据库中的 AI 摘要缓存状态,返回缓存中的摘要内容
- 根据缓存状态决定是否调用 AI 生成摘要(首次生成或更新缓存)
- 通过 KV 锁机制控制 AI 调用并发
- 摘要缓存入库,首次摘要生成的页面此时返回结果
Cloudflare Summary Worker 部署简述
- GitHub 中 Fork cf-worker-summary 到自己账号下,并在 Settings - Secrets and variables - Action 中添加必要的变量,D1、KV、Cloudflre Token 需要先创建完成获取相应的参数,更详细说明可以阅读仓库的 ReadMe 以及 deploy.yml。
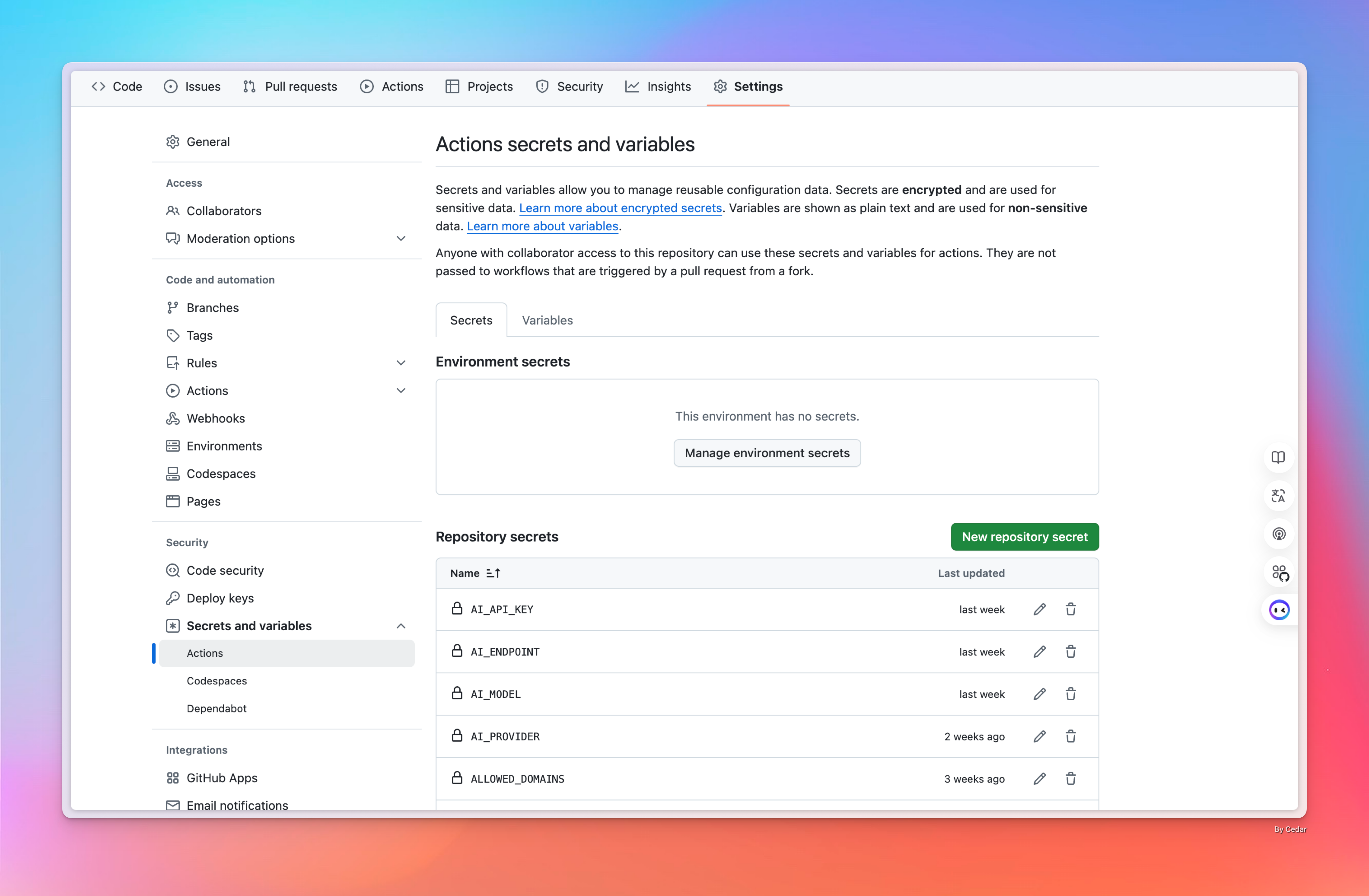
AI_PROVIDER:要使用的 AI 服务提供商(openai、anthropic 或 cloudflare)AI_MODEL:要使用的特定 AI 模型(例如,OpenAI 的 gpt-3.5-turbo)AI_API_KEY:您选择的 AI 提供商的 API 密钥AI_ENDPOINT:(可选)AI API 的自定义端点 URLALLOWED_DOMAINS:允许的文章 URL 域名列表,用逗号分隔CACHE_TTL:缓存生存时间(以秒为单位,例如 604800 表示 7 天)MAX_CONTENT_LENGTH:允许处理的文章内容的最大长度SUMMARY_MIN_LENGTH:生成摘要的最小长度KV_NAMESPACE_ID: 用于绑定 Worker KVD1_DATABASE_NAME: 创建的 D1 数据库名称D1_DATABASE_ID: D1 数据库的 ID,创建后可复制CLOUDFLARE_API_TOKEN: 用于发布 Worker 的 Cloudflare TokenSUMMARY_API: 用于调用的 API 地址,例如:api.example.comCLOUDFLARE_ZONE_ID: 可在 Cloudflare 域名页面中中找到
- 在 Cloudflare D1 中执行以下 SQL 完成库表创建以及基础数据的初始化。(此步骤非必需但建议)
CREATE TABLE summaries (
article_url TEXT NOT NULL,
summary TEXT NOT NULL,
model TEXT NOT NULL,
language TEXT NOT NULL,
created_at INTEGER NOT NULL,
PRIMARY KEY (article_url, language)
);
CREATE TABLE languages (
language_code TEXT PRIMARY KEY,
language_name TEXT NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO languages (language_code, language_name) VALUES
('en', 'English'),
('en-US', 'English (United States)'),
('en-GB', 'English (United Kingdom)'),
('en-CA', 'English (Canada)'),
('en-AU', 'English (Australia)'),
('en-NZ', 'English (New Zealand)'),
('en-IE', 'English (Ireland)'),
('en-SG', 'English (Singapore)'),
('zh', 'Chinese'),
('zh-CN', 'Chinese (Simplified, China)'),
('zh-TW', 'Chinese (Traditional, Taiwan)'),
('zh-HK', 'Chinese (Traditional, Hong Kong)'),
('zh-MO', 'Chinese (Traditional, Macau)'),
('zh-SG', 'Chinese (Simplified, Singapore)'),
('vi', 'Vietnamese'),
('vi-VN', 'Vietnamese (Vietnam)'),
('ta', 'Tamil'),
('ta-IN', 'Tamil (India)'),
('ta-SG', 'Tamil (Singapore)');
- 在 Action 中运行 workflow 即可等待完成 Cloudflare Worker 的部署。
API 接口说明
基础调用
- 使用
accept-language确定摘要语言的摘要生成服务,其中 url 参数指定为需要总结的页面
GET https://your-worker-url.workers.dev/summary?url=https://example.com/article
- 指定特定语言摘要的接口,需要通过 lang 参数指定语言,比如:zh、en、en-US
GET https://your-worker-url.workers.dev/summary?url=https://example.com/article&lang=zh
响应格式
API 将返回一个 JSON 响应
{
"summary": "生成的文章摘要",
"model": "用于摘要的 AI 模型"
}
关于模型的选择
虽然默认只做了 OpenAI、Claude、Claudflare AI 的接口适配,但是多数 AI 厂商都选择兼容 OpenAI,无形中增加了可选模型的范围,所以整个体验也就测试了不少厂商的模型。
| 模型 | 厂商 | 感受 |
|---|---|---|
| deepseek-chat | 深度求索 | 1. 中文摘要很出彩,相同的 Prompt,要强于千问1.5 2. 价格应该是最低的,在访问量相近、缓存策略相同的情况下,费用远低于月之暗面 |
| moonshot-v1-8k | 月之暗面 | 1. 中文摘要依然很强,需要调教一下 Prompt 2. 费用应该是高于 deepseek,但是最终摘要质量相差不大 |
| llama-3.2-90b-text-preview | Meta | 1. 中文摘要质量不算差,只是偶尔会有中英混合的情况以及乱翻译的情况(Cloudflare 变成 云flare) 2. 使用的免费服务,价格消耗不太确定 |
| qwen1.5-14b-chat-awq | 阿里 | 使用的 Cloudflare AI 中的模型,完全可以胜任中文摘要使用 |
| gpt-4o-min | OpenAI | 多语言支持很好,在产出非中文摘要时,有些带有中文文化色彩的名词会保留(比如:过年) |
选用的模型单纯在摘要产出这样的简单应用层面,都能够达到很好的效果,只是在 prompt 方面可能需要一些不同的调整和优化(先天不足,后天可补)。更大的模型确实表现的效果会更好一些,但结合实际的应用场景,响应速度、价格才是更应关注的层面,这也是在实现这套摘要逻辑时引入了缓存以及锁机制的原因。
未来规划(非计划):一点想法
AI 接口考虑整体使用独立 Cloudflare Workers 部署,外部应用可以使用统一的接口调用,扩展 AI 支持上会更方便,同时不影响下游应用。接口上按照默认 AI 调用队列、指定特定 AI 模型、指定特定 AI 调用队列三种方式应该足够满足使用场景。